
Big Data Testing – Understanding the complex world of Data Testing Strategy

With the advancement in technology, a massive amount of data is collected every second. Big data is a buzzword that is used by huge companies who have an enormous amount of data to handle. Companies find a hard time in managing a plethora of information collected. There are significant challenges faced by organisations in end-to-end testing in optimum test environments. They require a robust data testing strategy.
What is big data?
Gartner defines Big Data as, “Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation”.
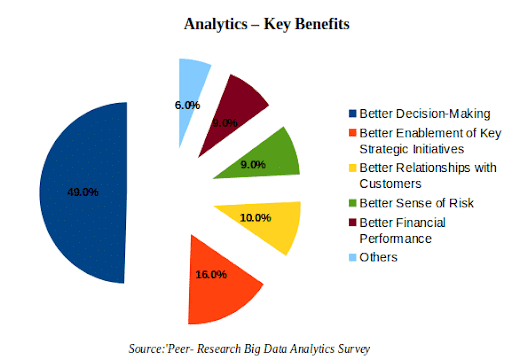
A survey of Deloitte, Technology reveals 62% of companies use huge data for assists in business. The following pie chart gives the reasons why companies use big data for analysis.
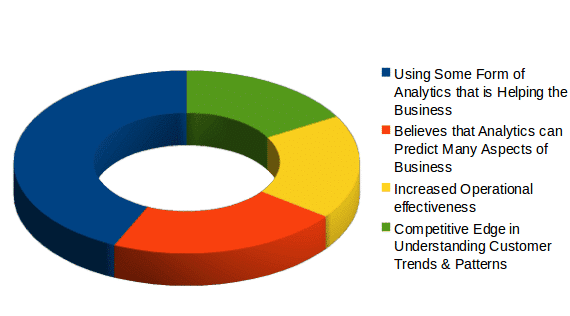 Image Source: https://www.edureka.co/blog/10-reasons-why-big-data-analytics-is-the-best-career-move[/caption]
Image Source: https://www.edureka.co/blog/10-reasons-why-big-data-analytics-is-the-best-career-move[/caption]
In simple words, big data means a large volume of data. For instance, Facebook generates 4 Petabytes of data every day with 1.9 billion active users and millions of comments, images and videos updated or viewed every second. This huge collected big data can be of any format, as:
- Structured
- Unstructured
- Semi-Structured
Structured Data – Highly organised data that can be retrieved using simple queries. Examples are – Database, Data warehouse ER and CRM. Data types of predefined structure come under this category.
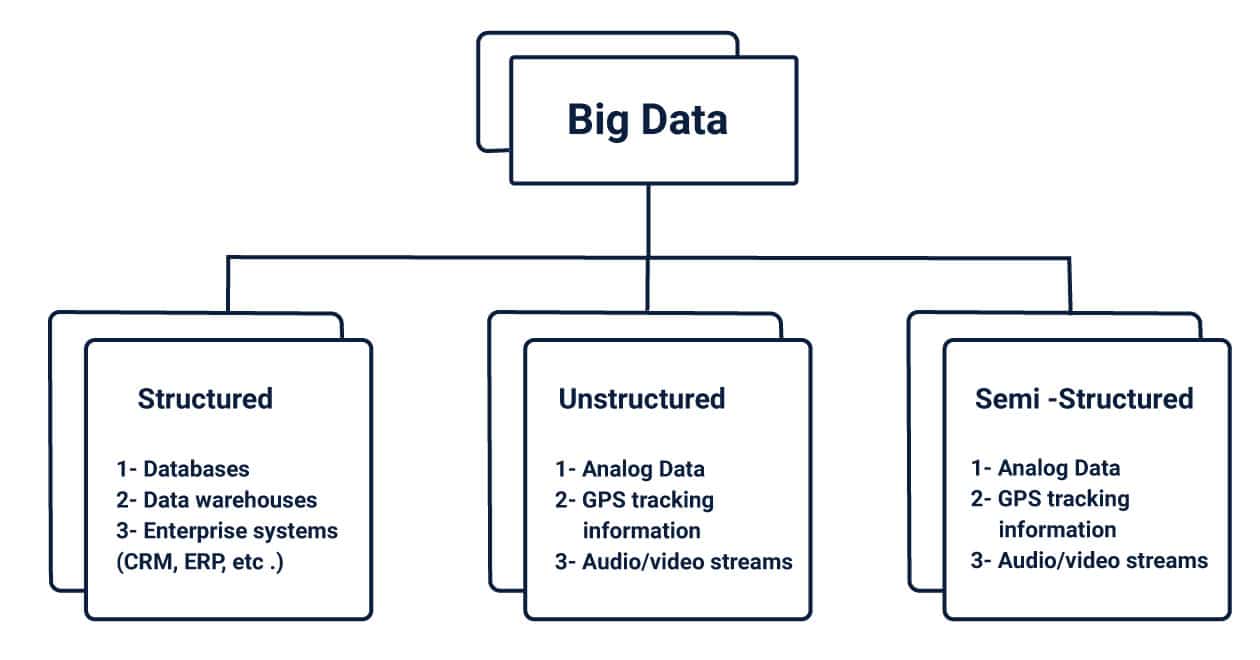
Unstructured Data – It does not have any predefined format and it is difficult to store and retrieve such type of data. For example images, videos, word documents, presentations, mp3 files and sensor data.
Semi-structured Data– The type of data which are no rigidly organised and contain tags and Metadata come under these types. Examples: XML, CSV and JavaScript Object Notation (JSON).
Below are few snippets of a sample XML file<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications with XML.</description>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-12-16</publish_date>
<description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description>
</book>
</catalog>
Below is a snippet which explains JSON content{
"firstName": "Adam",
"lastName": "Levine",
"age": 22,
"address":
{
"streetAddress": "18 Elm Street",
"city": "San Jose",
"state": "CA",
"postalCode": "94088"
},
"phoneNumber":
[
{
"type": "home",
"number": "845-156-5555"
},
{
"type": "fax",
"number": "789-658-9874"
}
]
}
What is Big Data Testing?
Such huge data collected needs to stored, analysed, and retrieved strategically. They undergo various testing procedures to understand their characteristics and usage. The primary characteristics of Big Data are:
- Volume,
- Velocity,
- Variety
- Veracity
- Value
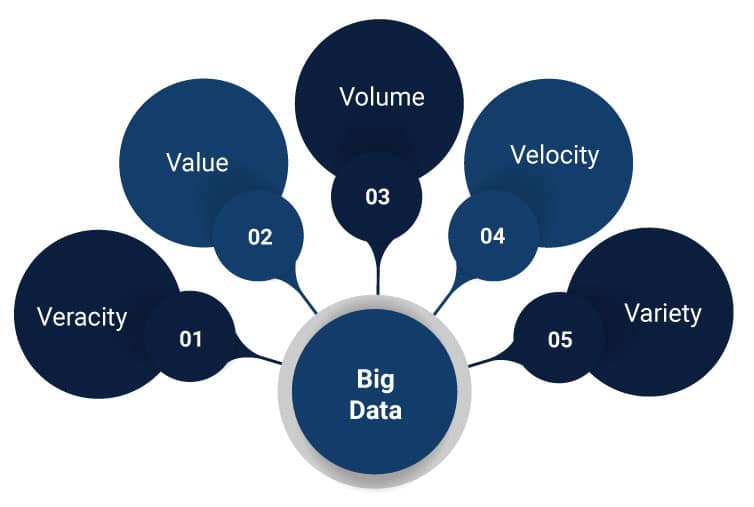
Where,
- Volume denotes the size of the data,
- Velocity denotes the speed at which data is generated,
- Variety specifies the types of data generated,
- Veracity tells how trustworthy the data is and
- Value gives us the ideas of how big data can be turned into a useful entity in business.
The traditional relational databases like Oracle, MySQL, and SQL cannot handle such a huge volume of data.
Reasons why traditional databases fail to handle Big Data
- Oracle, MySQL, and SQL – They cannot handle the unstructured format of data as big data will be most of it.
- RDBMS – Any type of sensitive data like patients details, military details will be available and those cannot be saved in row and column format.
- Relational databases were not built to store unstructured data.
- They will be expensive and inefficient as they have to handle huge velocity of data.
- Different types of data have to be stored and retrieved like images, videos and presentations.
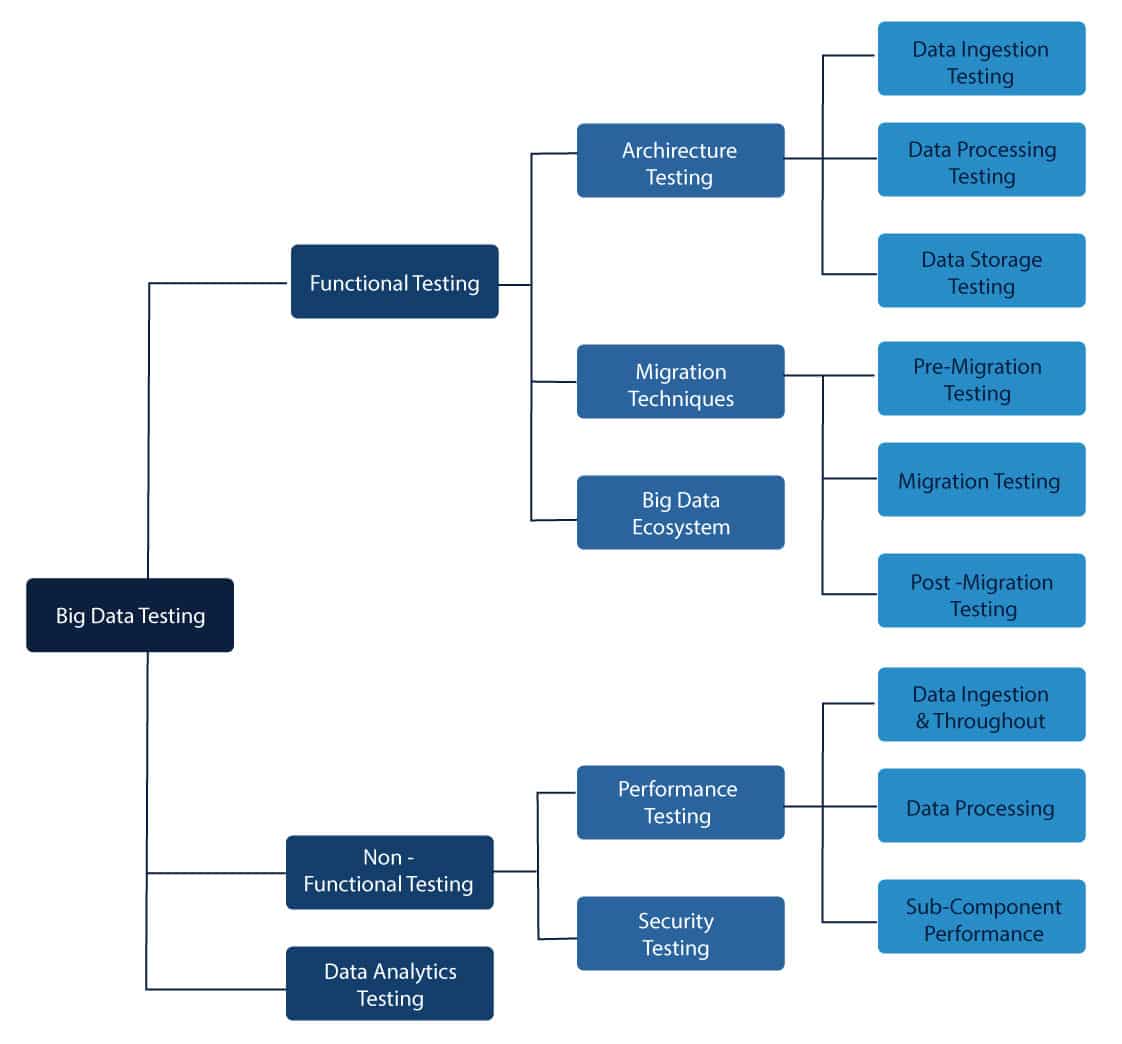
Types of Big Data Testing
There are several types of testing used for testing each characteristic of the data. The following smart art will help you with types of testing. These testing techniques have few requirements such as a) robust tools for testing automation b) well-skilled experts for testing c) ready to use processes to validate data movement. These testing methods are used to validate the Vs of Big Data – Volume, Velocity, Veracity and Variety.
Data Analytics and Visualisation testing are used to understand the volume of the data. The big data ecosystem testing validates the veracity of the data. The migration and source extraction testing validate the velocity for data. Finally, performance and security testing are done to validate a variety of data. The primary and most used types of testing are architecture and performance.
Data Testing Strategies – Key Components
As we are familiar with the Vs and the data types, we need to see the strategies involved in data testing. The key components in testing data are:
- Data validation
- Process validation
- Outcome validation
Data Validation
This is the stage where the data collected is ensured that it is not corrupted and accurate. This collected data enters the Hadoop Distributed File System (HDFS) for validation. Here the data will be partitioned and checked thoroughly in a step by step validation process. For these steps, the tools used are : a) Datameer, b) Talent and c) Informatica.
Simply, it ensures only the right data enter the Hadoop Distributed File System (HDFS) location. After this step is complete, the data is moved to the next stage of Hadoop testing system.
Process validation
This step is called Business Logic validation or Process Validation. In this step, the tester will check for business logic for different nodes at every node point. The tools used in Map Reduce. The tester has to verify the process and the key-value pair generation. Only after this step, the data validation is considered complete. Data is validated after the Map Reduce process.
Output Validation
The data is loaded downstream to check distortions if any, in the data. The output files which are created in the process are moved to the EDW (Enterprise Data Warehouse). Simply, it checks for data corruption.
The following flow diagram will explain the process more clearly.
Big Data Automation Testing Tools
Big Data uses numerous automation testing tools to integrate with platforms like Hadoop, Teradata, MongoDB, AWS, other NoSQL products etc. It is required to integrate with dev ops to support continuous delivery. These tools must have a good reporting feature, must be scalable, flexible to constant changes, economical and reliable. These tools are mainly used to automate repetitive tasks in testing of big data.
- HDFS (Hadoop Distributed File System)
- Hive
- HBase
- MapReduce
- HiveQL
- Pig Latin
Benefits of Big Data Testing
There are various benefits for companies which have a proper data testing strategy implied. Few of them are listed below:
Decision making – It mainly avoids a bad decision making. It helps in data-driven decision-making processes. When we have the data and analytics at hand, it eventually drives the decision making smooth and perfect.
Data Accuracy – 80% of the data which is collected is unstructured and by analysis of this data, businesses will be able to identify their weak spots to deliver better than their competitors.
To create a better strategy and enhanced market goals – It is easy to optimise the business data with all the collected data and assists in better understanding of current situations. This will help in creating better goals as per the current situations.
Minimizes losses and increases revenues – Even if we face a loss, it could be minimised with proper analytics of the data. It isolates different types of data to enhance customer relationship management.
Quality Cost – It comes at very less expensive methods that can be used for more revenue generation. It has a high return on investment (ROI).
Other benefits include- a) seamless integration, b) reduce time to market and c) reduce total cost of quality.
It is a necessity to test these data, if not it will affect the performance of the business. It helps in better understanding of the error, reasons for failures and sources of failures. If we have a proper method of analysing, then a few of the failures can be avoided.
Although it has more benefits, big data has a few disadvantages too, like – a) Technical Complexity, b) Logistical Changes c) Skilled Resources d) Expensive e) Accuracy of Results
Architecture Testing
This type of testing is to see how well data is organised. It is necessary to test the performing, what are the problems or errors in which the data is not performing well.
Data Ingestion Testing
This type of testing uses tools like – Zookeeper, Kafka, Sqoop, and Flume to verify whether the data is inserted correctly. The following code is for storing and retrieving data:<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>jQuery.data demo</title>
<style>
div {
color: blue;
}
span {
color: red;
}
</style>
<script src="https://code.jquery.com/jquery-3.4.1.js"></script>
</head>
<body>
<div>
The values stored where
<span></span>
and
<span></span>
</div>
<script>
var div = $( "div" )[ 0 ];
jQuery.data( div, "test", {
first: 16,
last: "pizza!"
});
$( "span" ).first().text( jQuery.data( div, "test" ).first );
$( "span" ).last().text( jQuery.data( div, "test" ).last );
</script>
</body>
</html>
Data Processing Testing
This type of testing uses tools like Hadoop, Hive, Pig, Oozie to validate whether business logic is correct.
Data Storage Testing
This type of testing uses tools like HDFS, HBase to compare output data with the warehouse data. Test Query for storage in HDFS is given in the sample below:**
* Key In, Value In, Key out, Value out
*/
public static class Map extends MapReduceBase implements Mapper {
public void map(LongWritable key, Text value, OutputCollector output, Reporter reporter) throws IOException {
String line = value.toString();
String[] lineAsArray = line.split("t");
String currentCurrency = lineAsArray[4];
String amountAsString = lineAsArray[5];
String sens = lineAsArray[6];
DoubleWritable data = null;
if("Debit".equals(sens)){
data = new DoubleWritable(Double.parseDouble("-" + amountAsString));
}
else if("Credit".equals(sen)) {
data = new DoubleWritable(Double.parseDouble(amountAsString));
}
output.collect(new Text(currentCurrency), data);
}
}
Performance Testing Approach
Since big data uses a large volume of data, it creates bottlenecks in the process and impacts the performance of the application. The metrics measured in this process are: a) throughput, b) memory utilization, c) CPU utilization, d) time taken for task completion. The following flow diagram will explain the process of performance testing in detail: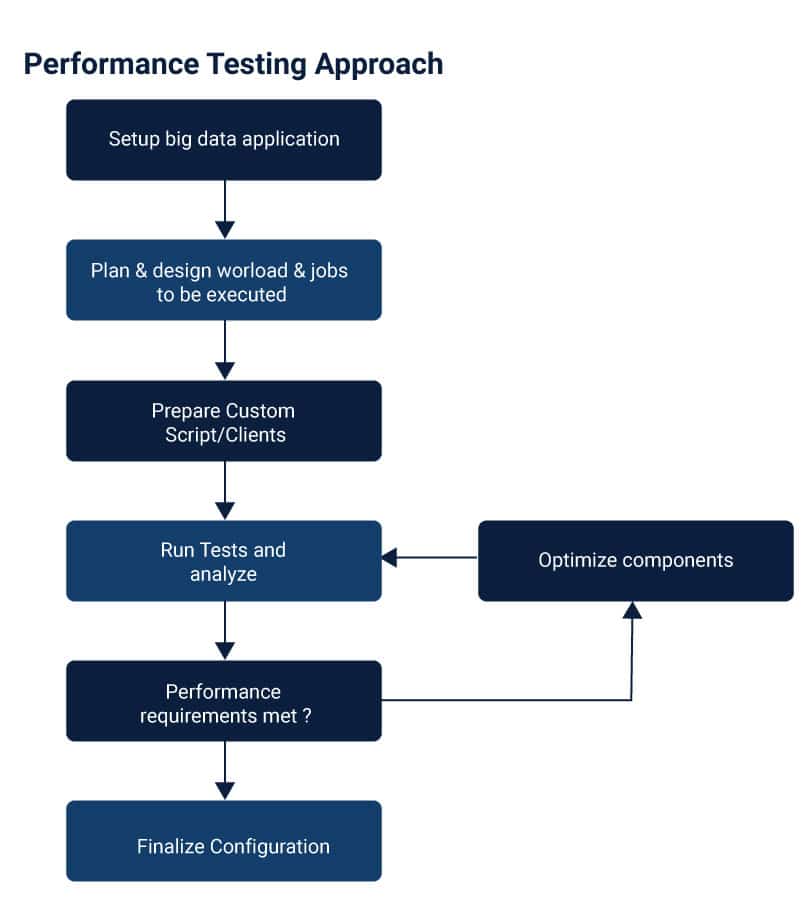
The parameters used in Big Data testing are:
Table – Parameters of Big Data Testing
| Parameter | Reason |
| Data Storage | Storage at different nodes |
| Commit logs | How much Commit logs grows |
| Concurrency | Performance of write and read operation |
| Caching | Row cache and Key cache |
| Timeouts | Values for connection timeout, query timeout, etc. |
| JVM Parameters | Heap size, GC collection algorithms, etc. |
| Map reduce performance | Sorts, merge, etc |
| Message queue | Message rate, size, etc |
Data loading and throughput
In this type of testing the tester checks how fast the system can get through the data at every stage. It checks how fast data can be injected into the fundamental data store. Example – Rate of insertion into Mongodb and Cassandra database.
Data Processing Speed
The speed of the data processing is tested here like how queries and map-reduce perform here. Data processing within data sets are also included here. Example – The running of Map Reduce jobs on the underlying HDFS.
Simple program to show how map reduce calculates word count:import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer it = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Sub-Component Performance
It identifies how multiple components of the data are performing. It is necessary to know how query is performing or map reduce is working. For example – how swiftly message is indexed and consumed. The following is a code snippet explaining simple query of 10 revenue generating products:-- Most popular product categories
select c.category_name, count(order_item_quantity) as count
from order_items oi
inner join product p on oi.order_item_product_id = p.product_id
inner join categories c on c.category_id = p.product_category_id
group by c.category_name
order by count desc
limit 10;
Thus, data testing strategies are compelling and the results of using data testing are beneficial. Companies use them to generate revenues. The term big data is not a buzzword anymore as we it is becoming a necessity every day. Garter revealed in 2014 that in the next few years 70% of all the business will be depending on big data for business intelligence.