
Choosing Right Machine Learning Model Combinations For Business Problem At Hand

Introduction
The machine learning systems have been around since the 50s, but there are three major factors at play. They are improved algorithms, more powerful computer hardware, and enormous increase of data. This is the reason why machine learning has gained a lot of significance than it had in the 50s.
So, what is machine learning? A form of AI(Artificial Intelligence) that enables computers to learn by way of experience and observation without being explicitly programmed is known as Machine Learning.
The basic theory behind machine learning is to develop algorithms that can take input data and utilize statistical analysis for predicting an input value within an acceptable range.
When you train your machine learning algorithm with your training data-set, the output that gets generated is the machine learning model.
After reading this post, you will gain knowledge on choosing right combination of machine learning models for business problem at hand.
In this article, I will first talk about different machine learning algorithms as the model is obtained from training them with a data-set. Then, I will explain the machine learning models and model selection using cross validation. I will also let you know what kind of models are used for different requirements.
For choosing the right ML technique, you can use the ML cheat sheet as below.
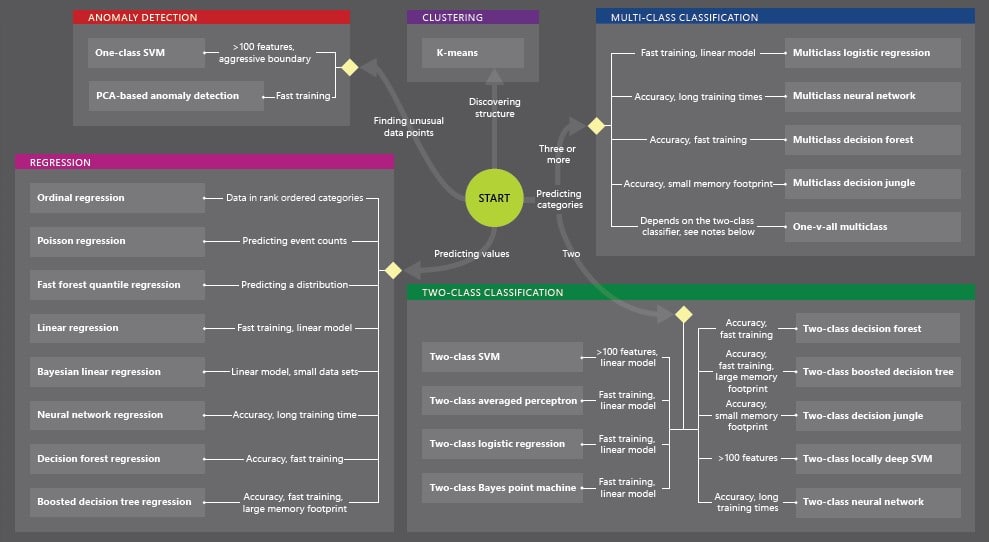
Types of Machine Learning Algorithms
Basically there are three kinds of machine learning algorithms. They are categorized as supervised learning, unsupervised learning, and reinforcement learning algorithms.
- Supervised Learning
Supervised algorithms basically involve the function approximation concept where we train an algorithm and at the end of the process, we opt for the function that best describes the data provided at the input. In this learning, we cannot figure out the actual function that always makes the accurate predictions.
The major kinds of supervised learning problems include classification and regression problems. Regression problems refer to when the value at the output is a continuous number. And, classification problems refer to when the value at the output belongs to a finite and discrete set.
The popular examples of supervised learning include Logistic Regression, KNN(k-nearest neighbors), Random Forest, and Decision Tree.
- Unsupervised Learning
In this type of learning, we don’t have any outcome or target variable to estimate or predict.
This algorithm is utilized for clustering a population into distinct groups, which is widely used for dividing customers into distinct groups for a particular intervention.
The major kinds of unsupervised learning algorithms include Association Rule Learning and Clustering algorithms. Here, the program is provided with a large amount of data and it must locate relationships and patterns therein.
The popular examples of unsupervised learning include K-means and Apriori algorithm.
- Reinforcement learning
The machine is trained to make particular decisions using this algorithm. This is not like any of the previous algorithms as we do not have unlabeled or labeled datasets here.
Reinforcement Learning works with exposing the machine to an environment where the machine trains itself continuously using trial and error. The machine learns from the previous experiences and tries to gain maximum amount of knowledge to make correct decisions.
The popular examples of reinforcement learning include Markov Decision Process.
- Machine Learning Models
Till now, you have seen different machine learning algorithms. When you train your machine learning algorithm with your training data-set, the output that gets generated is the machine learning model.
I have stated this definition in the ‘Introduction’ section as well. Take for example, linear regression algorithm is a technique to fit the points to a line, y = mx + c. Suppose, after fitting the points, if the line y = 5x + 3 is obtained. Then, this is a model.
Putting this in more simple terms, a machine learning model is nothing but any object that is created in machine learning after training from a machine learning algorithm.
For any machine learning project, the selection of right machine learning model is a crucial part, and as they are many to choose from, determining their weaknesses and strengths in various business applications is highly essential.
Machine learning models possess the capability to predict patterns depending on previous experiences. These models find repeatable, predictable patterns that can be applied to data management, e-commerce, and new technologies like autonomous cars. In the below section, we will see how to choose a machine learning model for solving business problems.
Model Selection using Cross-Validation
For choosing the right machine learning model for solving business problems, model selection using cross-validation is what we need. Model selection is the process of choosing a statistical model from the set of given models and data provided.
A technique that evaluates the predictive models by segmenting the original sample into a test set to evaluate the model, and a training set to train the model is known as cross validation. Let us understand how the model selection is done using cross-validation.
- Cross-validation
In cross validation, for partitioning the dataset into into k equal-sized, non-overlapping subsets(folds), train a model using k-1 folds and predict the performance of that model utilizing the fold that you left out. Do this for each possible fold combinations(first leave out the 1st fold, then 2nd,…and then kth fold, and train using remaining folds).
After completing this, estimate the mean performance of all folds(also the standard deviation/variance of the performance). The selection of parameter k is based on the time you have. For k, the usual values are 3,5,10 or N where N is your data size.
- Model Selection
Let’s imagine you have 5 methods(KNN, SVM(Support Vector Machine), ANN(Artificial Neural Networks), and so on) and 10 parameter combinations for every method.
You just have to run cross validation for every method and parameter combination(5*10 = 50) and choose the best method, model, and parameters. Then, with best methods and parameters on all your data, you re-train and you have your final model.
For example, you utilize many methods and parameter combinations for each, it is highly unlikely that you will overfit. In these kind of cases, you must use nested cross validation.
- Nested Cross-Validation
The cross-validation is performed on the model selection algorithm in nested cross validation. This involves splitting your data into k folds at first. Then you select k-1 data sets as your training data and the one that is remaining as the test data after each step.
Then for every possible combination of the k folds, you run the model selection(the process explained above). You test every model after that with the test data that is remaining and select the best one.
After having the last model, you train a new one again with the same parameters and method on all the data that you have. That will be your final model.
Utilization of Machine Learning Models for Different Purposes
If you need to train incrementally – you must use Bayesian if you need to frequently update your classifier with new data. SVM and Neural networks need to work on training data in one go.
If you have a categorical/binomial data – bayesian works best with binomial/categorical data. If you need to understand the working of a classifier, you can use decision trees or bayesian as they can be easily explained.
For higher classification speeds, SVMs are the best as they are required to determine only on which side of line your data exist. SVMs and Neural networks are the best when handling complex non-linear classification.
In Spite of an apparent simplicity, the linear classifier and linear regression machine learning models are useful on a large amount of features where better models suffer from overfitting.
With a linear combination of parameters and sigmoid(nonlinear function), logistic regression is the simplest non-linear classifier and it is used for binary classification.
In compositions like gradient boosting or random forest, decision trees are used. K-means can be perfect as a baseline in various problems. PCA(Principal Component Analysis) is great for reducing your feature space dimensionality with minimal information loss.
Wrap-Up
Ultimately, the ideal machine learning model to utilize for any given business problem depends on how the results will be used, the available data, and the domain expertise of a data scientist on the subject.
Understanding how they vary is a major step to make sure that every predictive model your data scientists develop and deploy gives valuable results.