
Leveraging Jupyter Notebooks: A Complete Guide

What is Jupyter Notebooks?
It is an open-source web application that enables users to make and offer codes and reports.

- It gives a domain, where you can archive code, run it, take a look at the results, envision information and see the outcomes without many hiccups.
- This makes it a helpful device for performing end to end investigative information processes for data such as data cleaning, measurable displaying, building and preparing machine learning models, imagining information, and many, numerous different employments.
Decoding Jupyter Notebooks
Jupyter Notebooks truly flounce when you are still in the prototyping stage. This is on the grounds that your code is composed of independent cells, which are executed independently.
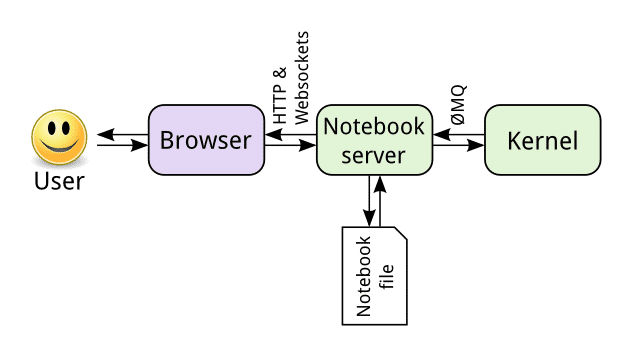
- The Notebooks are extraordinarily adaptable, intelligent and great instruments in the hands of a data scientist and play a key role in leveraging tasks in many companies.
- They even enable you to run different languages other than Python, similar to R, SQL, and so on. Since they are more intelligent than an IDE stage, they are generally used to show codes in a more instructive way and reduce the need for postoperative debugging and control.
- All things considered, think about it as an open source, cross stage IDE platform. Languages like Python, R, Julia and so forth accessible inside the application imply that it keeps on profiting from fast advancement occurring inside them especially within new libraries.
The Jupyter Notebook kernel specifically has software add-ons to make the process seamless when exporting data to places other than the Jupyter notebook environment.
What Do The Notebooks Contain?
Jupyter Notebooks are a well known computational platform for data researchers and engineers. Consider Jupyter Notebooks as a record that contains code (Python, R, Julia and so forth.), charts, conditions and obviously, remarks to depict the code.
In that sense, an example of Jupyter Notebook speaks to data scientist in a way that tasks can be executed progressively under one umbrella. The Jupyter Notebook environment has a user-friendly IDE and the jupyter notebook editor where the code is inserted into the mainframe.
The jupyer notebook for windows has a separate call command where the softwares are linked together and can be viewed under the jupyter notebook terminal.
 Source:- https://medium.com[/caption]
Source:- https://medium.com[/caption]
- At The Crux
- It can be altered and kept running from the program. The execution of the journal itself occurs on the server through the thought of a Kernel.
- Jupyter Notebooks can be effectively incorporated with enormous data storing centres like Apache Spark. It can likewise be facilitated inside Docker compartments.
- Commonly used services
- Microsoft Azure uses a version of Jupyter Notebooks for dealing with data. You can utilise this support in R and Python as well. You can likewise manufacture an ML show than send it to Azure.
- Custom counts (comparative Excel Services and HPC) are done by inspecting a portion of the key capacities. To be clear, this isn’t a contention against utilising Excel. With its close omnipresent use inside organisations, Excel-based custom estimations can be written without adopting any new abilities.
- Working with Notebooks requires the utilization of languages like Python and R.
- At last, the way that Jupyter Notebook is intended to keep running on the server from the beginning (not at all like Excel, which is essentially a work area application) and it’s joining with Spark and compartments implies that it can offer more noteworthy adaptability and financially savvy methods for facilitating them.
- For instance, execution can be offloaded to a PaaS Service like Azure Batch utilizing picture accessible on Jupyter Notebook Docker Hub. This expels the need to set up and deal with a bunch like HPC.
 Source:- https://stackoverflow.com[/caption]
Source:- https://stackoverflow.com[/caption]
The Docker Hub acts as a great drive for saving projects without extra space requirements and disk augmentations.
Why should you use it?
- Independent, shareable unit of work
- Conceptually like an Excel exercise manual, it is an archive that consolidates code, remarks, charts and can be effortlessly shared utilizing email, GitHub, Dropbox, and so forth.
- Intelligent Execution Environment
- Like Excel, you can see creator recipes and plot graphs intuitively. You can basically choose a phone and execute it utilising the “play” catch appear in the toolbar underneath.
- Capacity To Work With Cells And Sheets
- At the essential level in Excel, you work with a lattice of cells where every cell is referenced by a letter-number location. Jupyter by means of Python libraries like pandas offer a comparable ability.
- DataFrame offers a two-dimensional structure with named lines and segments. The accompanying model populates a DataFrame ‘df’.
- Capacity to conjure libraries in different langauges like C/C++ (like Excel Add-ins)
- Since Python underpins connecting with outside libraries written in languages other than Python, Notebooks can use this extensibility to reuse existing libraries with no effort. This is a case of a great way for a C++ library to be utilised in the software.
- Automatic Invocation of the Jupyter scratch pad
- Jupyter Kernel entryway is a web server layer that gives UI less access to Jupyter Kernel. This piece enables approaching solicitations to be served by executing the commented on note pad cells. This empowers a non-intuitive correspondence channel between REST customers and Jupyter Notebook.
 Source:- https://medium.com[/caption]
Source:- https://medium.com[/caption]
Getting Started With Jupyter Notebooks
The idea is to naturally spare a duplicate of the journal in both Python content and HTML design at whatever point the note pad is spared. The usual method of doing so involver clearing all the output in the note pad before submitting it to the form control to produce an improved history cleaner.
But this tends to bring out many issues, namely:-
- On the off chance that during the data preparation stage, some portion of the note pad requires over ten minutes to run, it would make a solid motivating force for the analyst to skip really running the scratch pad, and rather simply read through the code and accepting it does what it seems to do.
- This is accepting the prepared model is serialized somehow for the commentator to stack, else it might take hours to prepare on analyst’s framework.
- There’s no simple method to circulate the information and model documents alongside the note pad. Putting away and exchanging gigabytes of information isn’t that simple for information researcher, and requesting that information engineers construct something inside only for this may not be financially savvy.
- For “Huge Data” situation, you wouldn’t have any desire to spare Spark get to accreditation inside the note pads (extremely perilous), so you’d have to discover some approach to deal with the bunch safely.
- There’s another structure called Data Version Control that looks encouraging. Be that as it may, you’d have to pay charges to Google or Amazon for the distributed storage.
- With everything taken into account, the most direct approach to tackle these issues is to simply incorporate the yields of the note pad in the variant control.
Convert the journal to a Python content and an HTML document. Utilize the Python content to do code diff in the survey procedure. HTML record works best as a connection in cross-group correspondence messages. The following steps must be taken in order to leverage data best done using applications insight.
 Source:- https://blog.sicara.com[/caption]
Source:- https://blog.sicara.com[/caption]
Jupyter Notebook Installation
For a perfect Jupyter notebook installation, there may be large differences in the procedures depending upon the operating system in use.
- Windows
- Installation for Windows can be done by downloading the kernel kit from the website and confirming the latest security code for the other bundled softwares.
- Mac
- Installation for Mac requires special proprietary confirmation from the development team due to a difference in Jupyter Notebook architecture on the IDE for Mac OS.
- Linux
- For installing in Linux, special hash comments and commands have to be entered for the purpose of downloading and repackaging bundles. Users may also find it a bit tedious to work with windowless environments but can be handled through extensions after repackaging.
- Users can also have it downloaded and repackaged from the cloud.
What To Do
- Create a Notebook
- Draft a new Notebook or clone an existing one. While Jupyter supports various programming languages, it’s best to carry this out while you have Python 2.7. It is often bundled as Jupyter Notebook R, Jupyter Notebook Matlab and even Jupyter Notebook Scala.
- The Jupyter Notebook R bundle aptly connects both softwares and is suitable if the github extension is installed making it great for reasonably sized datasets.
- However, if leveraging larger datasets, the Jupyter Notebook Matlab bundle is recommended but can often bring some disarray due to the latter’s proprietary nature.
- Collect And Query data from Application Insights
- To query for data, fill in the Application ID and an API Key which are needed. Both can be found in Application Insights portal near the API Access blade and under Configure. You can receive more information by accessing the API.
!pip install –upgrade applicationinsights-jupyter
from applicationinsights_jupyter import Jupyter
API_URL = “fhttps://api.aimon.applicationinsights.io/”
APP_ID = “REDACTED”
API_KEY = “REDACTED”
QUERY_STRING = “customEvents
| where timestamp >= ago(10m) and timestamp < ago(5m)
| where name == ‘NodeProcessStarted’
| summarize pids=makeset(tostring(customDimensions.PID)) by cloud_RoleName, cloud_RoleInstance, bin(timestamp, 1m)”
jupyterObj = Jupyter(APP_ID, API_KEY, API_URL)
jupyterObjData = jupyterObj.getAIData(QUERY_STRING)
- Send Back Derived Data To Application Insights
- To send data to an Application Insights resource, you need to use the Instrumentation Key. As always, it can be found in Application Insights portal, on the Overview
!pip install applicationinsights
from applicationinsights import TelemetryClient
IKEY = “REDACTED”
tc = TelemetryClient(IKEY)
tc.track_metric(“crashCount”, 1)
tc.flush()
- Execute the Notebook
- To execute the Notebook, either use the platform IDE using the Python command line kernel or by using Azure WebJob which is the most preferred mode of execution. To do so, the Notebook, its dependencies, and the Jupyter server have to be uploaded to the Amazon Web Services container.
 Source:- https://blogs.msdn.microsoft.com[/caption]
Source:- https://blogs.msdn.microsoft.com[/caption]
What You Will Need To Prepare
- Resources Needed
- Download the Notebook and install Jupyter server using Anaconda. Jupter Notebook Anaconda facilitates its components to be shared faster with the Anaconda IDE.
- Execute the Notebook on your machine and install all dependencies, as App Service container does not allow the directories to be changed where the modules would otherwise be installed automatically.
- Update the path in a dependency to and replace the first script in Anaconda2/Scripts/jupyter-nbconvert-script.py with
#!D:/home/site/wwwroot/App_Data/resources/Anaconda2python.exe - Update the local copy using pip commands.
- Create run.cmd file containing the following script
D:homesitewwwrootApp_DataresourcesAnaconda2Scriptsjupyter nbconvert –execute <Your Notebook Name>.ipynb - FTP resources
- Find deployment credentials and FTP connection information.
- FTP the Anaconda2 folder to a new directory in the resources folder.
- Create a new Azure WebJob and upload the Notebook to run the run.cmd file.
The Notebook runs four Node.js processes on each cloud instance. However, due to limitations of the SDK, no log ins can be done when crashes occur so be careful.
A custom event NodeProcessStarted is logged in the system when a new Node.js process starts in a cloud instance which all start simultaneously when they are recycled every 8-11 hours. This is another nifty way to check for recently crashed processes by seeing the number of NodeProcessStarted events that have occurred at a different frequency.
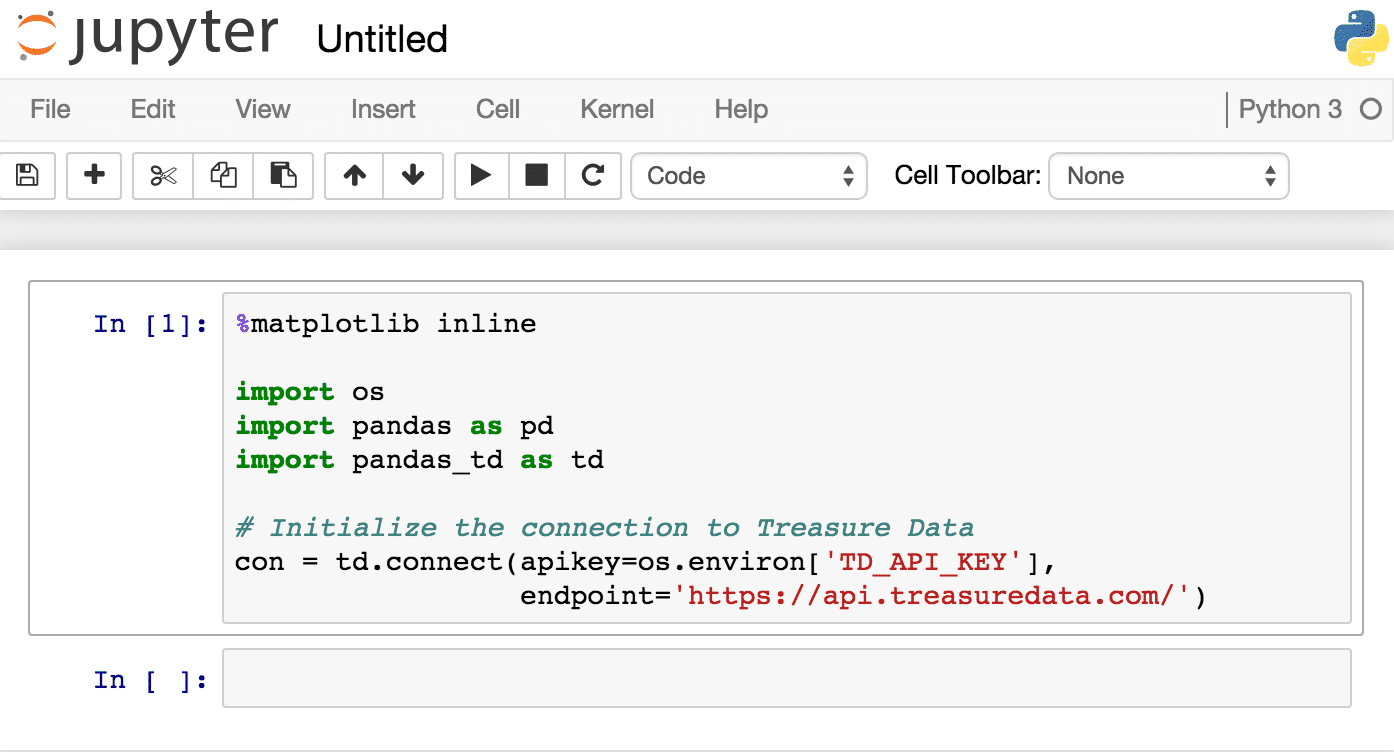 Source:- https://support.treasuredata.com[/caption]
Source:- https://support.treasuredata.com[/caption]
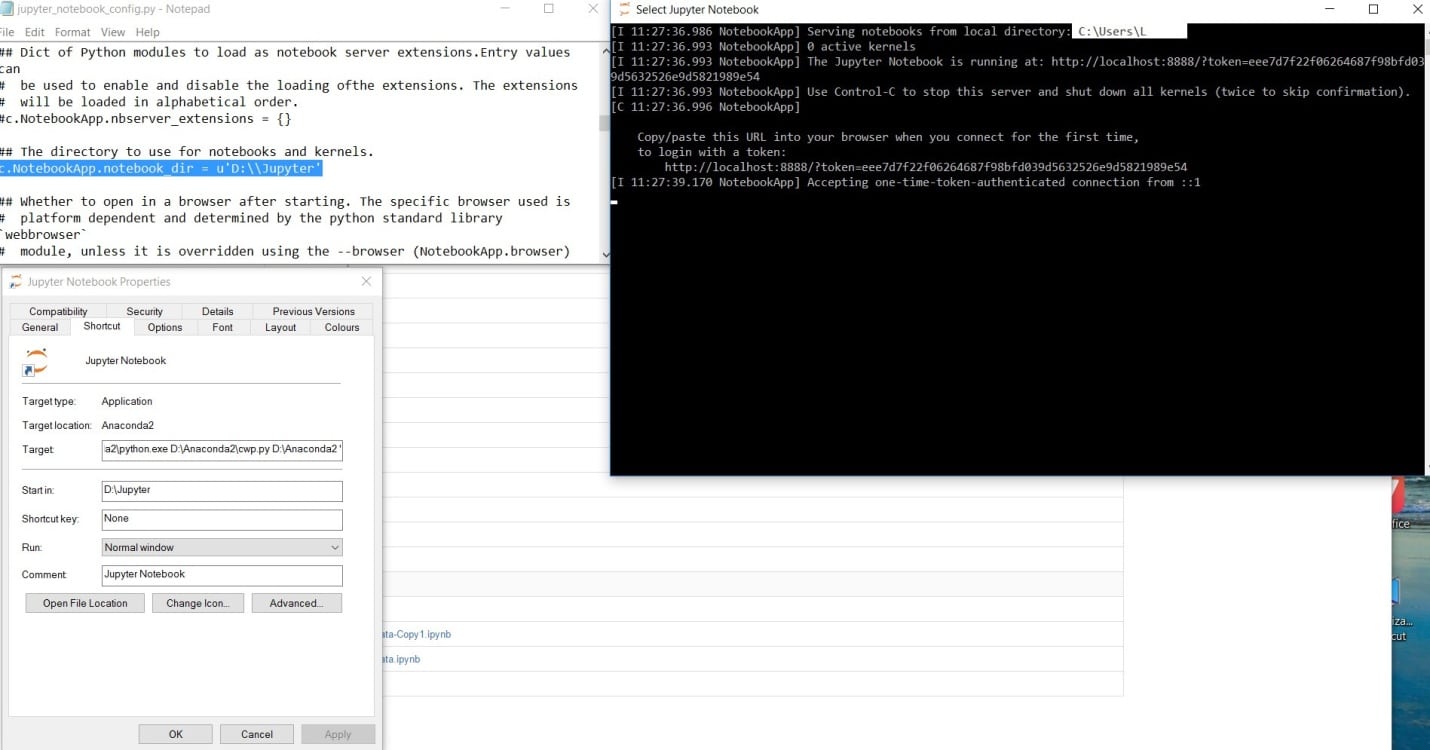
There are two ways to use the above script in a Jupyter environment:-
Paste it at the top of ~/.jupyter/jupyter_notebook_config.py and run jupyter notebook –generate-config to create it if you don’t have it yet.
Use export JUPYTER_CONFIG_DIR=~/.jupyter_profile2 to specify the config folder if in case there are different configurations for different projects.
Place it in the root-kit of the project folder (where you run the application command) as jupyter_notebook_config.py
 Source:- https://support.treasuredata.com[/caption]
Source:- https://support.treasuredata.com[/caption]
Leveraging Jupyter Notebook amid the Sprint Review
To begin with, the application is utilized to assemble models iteratively and ends up being an extraordinary method to help individuals getting an extremely solid feeling of the work that has been done on building Machine Learning models amid the Sprint.
- Utilizing the application along these lines makes conceivable to disclose the model to non-specialized individuals while enabling them to get great bits of knowledge into the internal procedures of the item your group is creating.
- Since Notebooks are visual, on the grounds that you can plot information, indicate tables and compose Markdown. It is a perfect device for such an exhibition of calculations that can’t be effectively shown something else.
The fundamental motivation behind the Sprint Review isn’t to clarify “how” the work has been done yet rather demonstrate the last outcome. Another great way to leverage includes using nbconvert. To illustrate how this can be done, let’s first see the various cells that make up the leveraging model
- Markdown cell
- A markdown cell is defined by a Python string. Since string literals are executed without a method call or preceding task, encoding markdown cells along these lines create no impact in execution.
- # This is an example of a Markdown cell. It can encode LaTeX
- General code cell
- A typical code cell is meant by “#>”. The lines tailing it are dealt with as Python to be executed regardless of the unique circumstance.
- Jupyter code cell
- The beginning of a Jupyter code cell is “#nb>” (“nb” remains for “note pad”). Each line tailing it expected to be in a similar cell should begin with a “#”, i.e. a Python remark character.
- This is on account of note pad just cells ought not to be run when executed as a content.
- Content code cell
- Content code cells are the supplement of Jupyter code cells. They are executed when kept running as a content however not in a scratch pad. They are defined by “#py>”.
- The device remarks out the majority of the code in the content code cell when changed over to a note pad.
- Leveraging These Tools in a Production Workflow
These instruments make building up a data science application that keeps running underway significantly less demanding. You can flawlessly switch between the scratch pad and content organisations. One minute you’re troubleshooting in Jupyter, the following you’re presenting twelve long-running occupations through the direction line.
- The majority of this is empowered with two scripts:
- # Convert journal to executable Python content $ to-content my-notebook.ipynb my-generation script.py
- # Convert a content improved with the predetermined configuration # to a scratch pad $ to-scratch pad my-generation script. Py my-note pad for-debugging.ipynb
Bringing Magic To Jupyter Notebook
The developers have listened to the community and have installed predefined functions that make leveraging easier and make the processing stage more fluid. Magic commands run in two ways- line-wise and cell-wise. You can run the below commands to practice out such capabilities by starting the commands with %lsmagic.
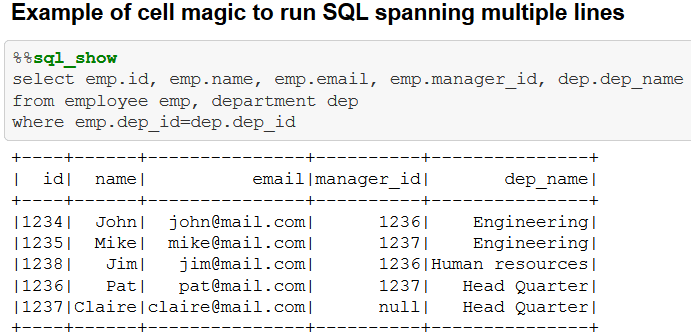 Source:- https://externaltable.blogspot.com[/caption]
Source:- https://externaltable.blogspot.com[/caption]
As the titles suggest, line-wise commands help in single line code execution while cell-wise commands execute the entire block of code in the entire cell
For example %time a = range(100) is a line wise code and %%timeit a = range (100) is a cell wise code.
 Source:- https://externaltable.blogspot.com[/caption]
Source:- https://externaltable.blogspot.com[/caption]
Next Step- Bringing Interactivity To Dashboards
Adding widgets is the next supposed and crucial step in leveraging data in Jupyter Notebooks.
First, add the following line of code- from ipywidgets import widgets.
 Source:-https://www.researchgate.net[/caption]
Source:-https://www.researchgate.net[/caption]
The basic type of widgets includes typical text input, input-based, and buttons. This will allow you to smoothly work on leveraged notebooks using simple keyboard commands which would be familiar with Excel enthusiasts, such as:-
- Press A to insert a new cell above the active cell, and B to insert one below the active cell.
- Press D twice in succession to delete a cell.
- Press Z to undo a deleted cell.
- Press Y to turn the currently active cell into a code cell.
- Press F to bring up the ‘Find and Replace’ menu.
- Press Ctrl + Home to go the start of the cell.
- Press Ctrl + S to save work.
- Press Ctrl + Enter to run your entire cell block.
- Press Ctrl + Shift + F to open the command palette.
Below is a list of magic commands that should be implemented for better coding in the python terminal. Similar commands can be used in the R terminal as well.
- Run %pdb to debug.
- Run %prun in order to do a performance run.
- Run %writefile to save the contents of a cell to an external file.
- Run %pycat to show the highlighted contents of an external file.
- Run %who to list all variables of global scope.
- Run %run to execute Python code or Jupyter Notebook R code.
- Run %env to set environment variables.
- Run %store to pass variables between notebooks.
- Run %load to insert code from an external script.
Share Your Results
Congratulations on creating and leveraging your first notebook. You might be eager to share your results but would be disheartened by the Notebooks’ default JSON file document that consists of text, source code, mdia output, and metadata. Each segment of the document is thus stored in a cell.
Click on the File option from the menu bar, and you will see a load of options to store and share the Notebook file. You can store it as an HTML, PDF, Markdown or reStructuredText, or a Python script or a Notebook file.
Use the nbconvert command to convert the Notebooks into other formats as:-
jupyter nbconvert –to html Untitled4.ipynb
You can even schedule runs for ETL and for reporting. In order to run reporting schedules, you just need to click on the scheduling options and choose a time format for days, weeks or months. For an ETL pipeline, use the advanced magic commands in your notebook in combination with some type of schedule.
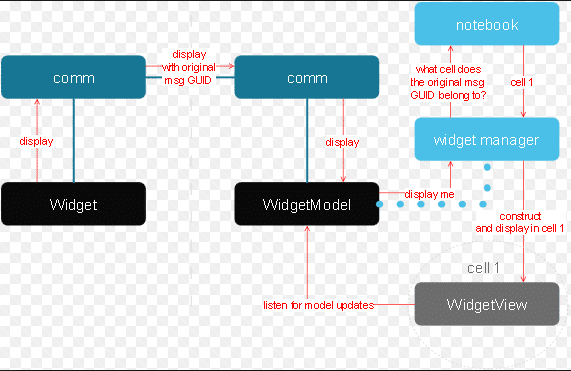 Source:- https://blog.jupyter.org[/caption]
Source:- https://blog.jupyter.org[/caption]
Final Notes On Leveraging
Once you have a leveraged notebook up and ready, load GitHub Gists from your notebook documents. With jupyterhub, you can spawn, manage, and proxy multiple instances of the the same notebook server. This is a great spot for providing notebooks to colleagues, associates, students, a corporate data science group, or maybe a scientific research group.
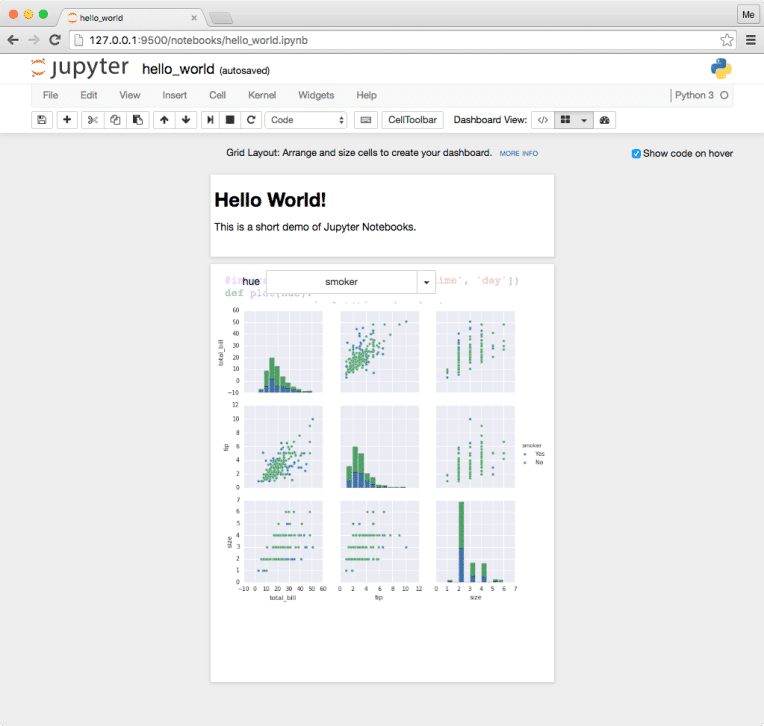
Keep in mind the following tips:-
- Take use of binder and tmpnb to produce temporary environments to reproduce your notebook execution and leveraging.
- Use nbviewer to render notebooks as static web pages and make them more accessible to clients and users.
- Turn to nbpresent and RISE to turn your Notebooks into handy slideshows instead of running towards Powerpoint extensions.
- Use the Pelican plugin to implement Notebooks as a blog.
- Use two types of notebooks for a data science project- a lab notebook and a deliverable notebook. The key difference is the fact that individuals can control the lab notebook and the deliverable notebook can be accessed by the whole data science team.
The true potential of Jupyter Notebooks can be best understood from downloading and running projects that use rich data with astounding results. Its multipurpose use as being a platform that combines the most popular data freeware should be a reason as good as any to start coding and leveraging.