
KSQL- Kafka for Data Processing

Data processing has become a cornerstone of the tech industry that has fashioned and seasoned itself to develop technologies to further pique into what it can offer.
As Big Data becomes more challenging, there are tools that can be used to develop some meaning and give data processing velocity and structure – KSQL being one of them.
KSQL : Apache Kafka’s SQL Engine for Data Processing
KSQL, a smashing SQL extension for Apache Kafka brings down the difficulty bar to the universe of stream preparation and KSQL data processing. It provides a basic and totally intelligent SQL interface for handling information in Kafka.
You never again need to compose code in a programming language, for example, Java or Python. It is an open-source (Apache Kafka 2.0 authorized), distributed, adaptable, solid, and ongoing. It bolsters an extensive variety of great stream handling activities including accumulations, joins, windowing, discretion, and significantly more.
Comparing KSQL with SQL
SQL or Structured Query Language began its journey is a great back end for data storage, manipulation and processing. SQL became a staple custom software for receiving information powered by its uniquely built DDL(Data Definition Language), and DML(Data Manipulation Language) commands that made inserting and modifying entries simpler.
All things considered, it is very well the next level to a SQL database. Most databases are utilized for doing on-request queries and adjustments to put away information.
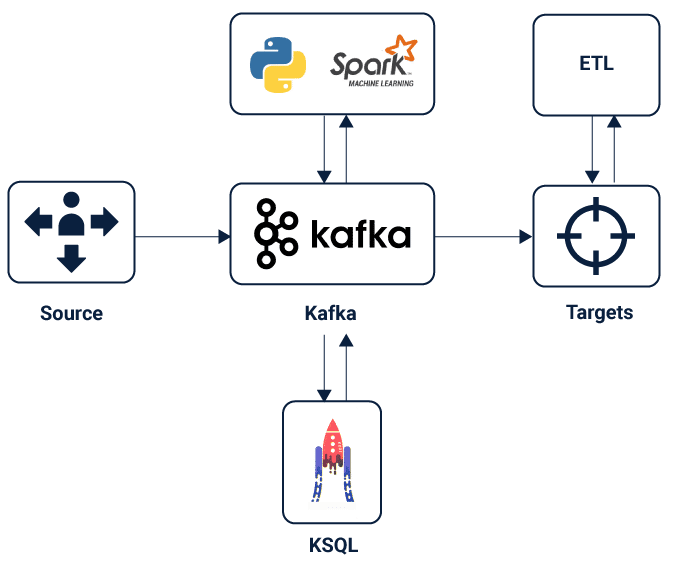
- KSQL doesn’t do queries (yet), what it does is persistent changes—that is, stream handling. For instance, envision a user with bundles of snaps from clients and a table of record data about those clients being consistently refreshed.
- It enables the user to show this flood of snaps, and table of clients, and combine the two. Despite the fact that one of those two things is unending.
- So what its runs are nonstop questions — changes that run ceaselessly as new information goes through them — on floods of information in KSQL Kafka
- Interestingly, inquiries over a social database are one-time questions — run once to culmination over an informational collection—as in a SELECT proclamation on limited lines in a database.
What Are the Components Of KSQL?
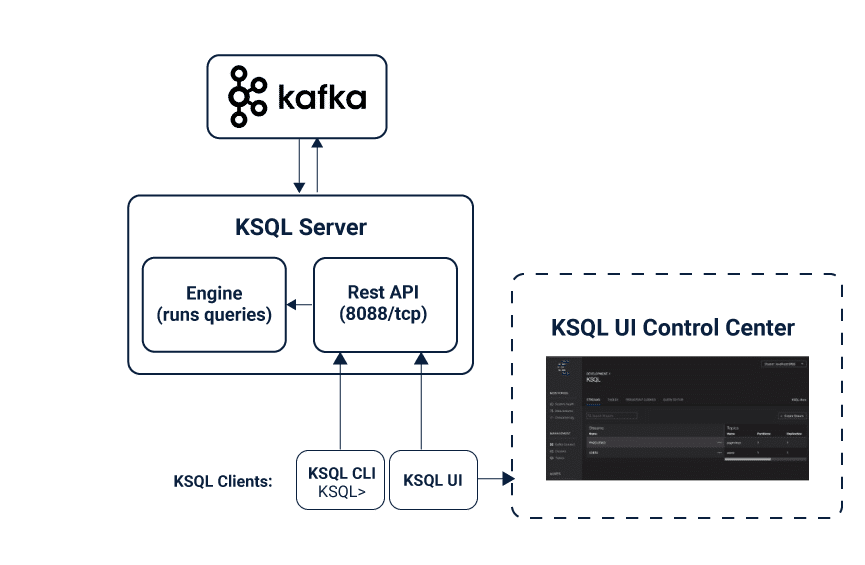
KSQL Architecture and Components
- Server
- The KSQL server runs the engine and processes the commands that executes it. This includes data processing, reading, manipulating and writing data to and from the target KSQL Kafka cluster.
- Its servers form clusters and can run as containers, virtual machines, and bare-metal machines.
- You can add and remove servers to/from the same clusters even during live operations to bring the full effect of its processing capacity as desired.
- You can deploy different clusters to achieve workload isolation as desired whenever possible.
- CLI
- You can also interactively write queries by using the command line interface (CLI) that acts as a client to the KSQL
- For production scenarios you may also configure its servers to function in what developers call non-interactive “headless” configuration, thereby preventing KSQL CLI access.
- Servers, clients, queries, and applications usually run outside of Kafka boundaries, in separate JVM instances, or in separate clusters entirely.
Why KSQL Is Good For Data Processing
- Continuous checks meet constant investigation
- One utilization of this is characterizing custom business-level measurements that are processed continuously which can be screened off, much the same as you do your CPU stack.
- Another use is to characterize a thought of rightness for your application and watch whether it is meeting this as it keeps running underway. Frequently when users consider observing the data, they consider counters and measures following low-level execution insights.
- These sorts of checks frequently can reveal to you that your CPU stack is high, yet they can’t generally let you know whether your application is doing what it is assumed to do.
- KSQL permits characterizing custom measurements of surges of crude occasions that applications produce, regardless of whether they are logging occasions, database refreshes, or some other kind.
- Make TABLE error_counts AS SELECT error_code, count(*)FROM monitoring_stream WINDOW TUMBLING (SIZE 1 MINUTE) WHERE compose = ‘Blunder’ is a sample code to perform this check.
- Security and irregularity identification
- Inquiries that change occasion KSQL Kafka streams into numerical time arrangement totals are drawn into Elastic, utilizing the KSQL Kafka-Elastic connector and imagined in a Grafana UI.
- Security use cases regularly take a considerable measure like checking and investigation. As opposed to application conduct or business conduct you’re searching for KSQL examples of misrepresentation, manhandling spam, interruption, or other terrible conduct.
- It gives a straightforward, advanced, and continuous method for characterizing these examples and questioning ongoing streams.
- For example, one command that can be used is:- Make TABLE possible_fraud AS SELECT card_number, count(*) FROM authorization_attempts WINDOW TUMBLING (SIZE 5 SECONDS) Gathering BY card_number HAVING count(*) > num;
- Online information reconciliation
- A significant part of the information handling done in organisations falls in the area of data improvement: remove information originating from a few databases, change it, consolidate it, and store it into a key-esteem store, look at lists, reserve, or other information serving framework.
- For quite a while, ETL — Extract, Transform, and Load — for data combination was executed as occasional cluster occupations. For instance, dump the crude data progressively, and afterwards, change it like clockwork to empower productive inquiries.
- Some use cases, this deferral is unsatisfactory. When utilized with Kafka connectors empowers a move from KSQL Kafka cluster information coordination to online information mixes.
- Take the example of the command, Make STREAM vip_users AS SELECT userid, page, activity FROM clickstream c LEFT JOIN clients u ON c.userid = u.user_id WHERE u.level = ‘attribute’;
- Application Development
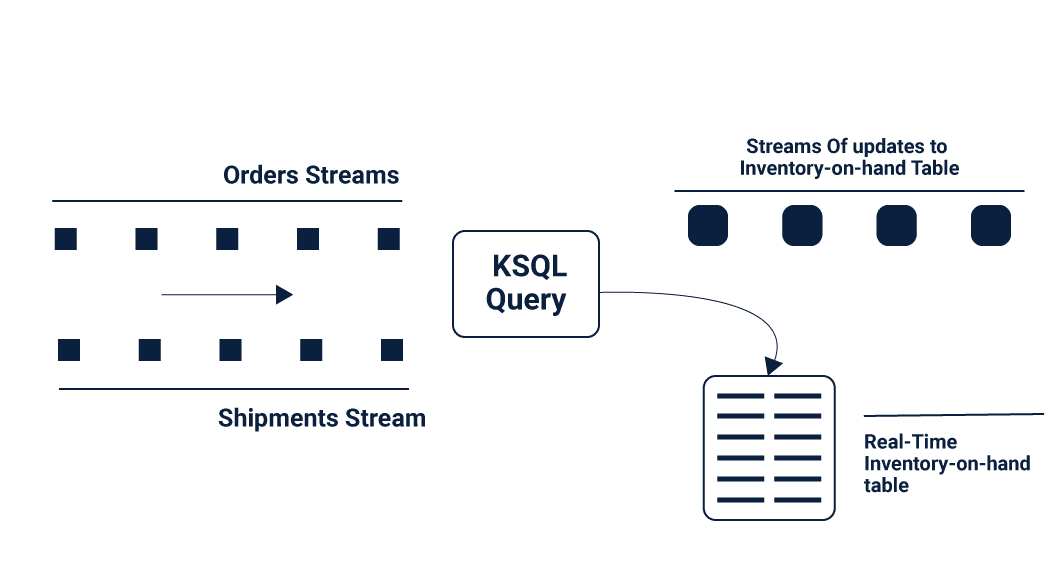
- Numerous applications change an information stream into a yield stream.
- For instance, a procedure in charge of reordering items that are running low in stock for an online store may benefit from a surge of offers and shipments to figure out a flood of requests to put.
- For more unpredictable applications written in Java, Kafka KSQL streams API might be only the thing. However, for basic applications or groups not keen on Java programming, a straightforward SQL interface might be what they’re searching for.
Data Processing Tools in KSQL
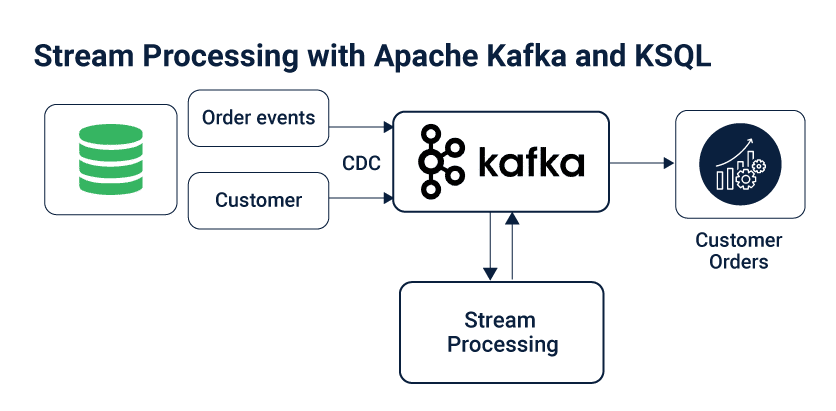
It utilizes Kafka’s Streams API inside, and they share a similar center for stream handling on Kafka. There are two center components that guide to the two central data storage containers in Kafka streams and enable you to control Kafka themes:
- Streams
- A stream is an unbounded succession of organised information (“certainties”). For instance, the developers could have a flood of monetary exchanges whose actualities can’t be changed. This implies new certainties can be embedded in a stream. However, existing realities can never be refreshed or erased.
- Streams can be made from a Kafka theme or from existing streams and tables. (Example:- Make STREAM site visits (viewtime BIGINT, userid VARCHAR, pageid VARCHAR) WITH (kafka_topic=’pageviews’, value_format=’JSON’));
- Table
- A table is a perspective of a STREAM or another TABLE and speaks to a gathering of developing certainties.
- Certainties in a table are variable, which implies new actualities can be embedded in the table, and existing realities can be refreshed or erased. Tables can be made from a Kafka subject or got from existing streams and tables.
- Ponder on the command and check out what happens when you use it-Make TABLE clients (registertime BIGINT, orientation VARCHAR, regionid VARCHAR, userid VARCHAR) WITH (kafka_topic=’users’, value_format=’DELIMITED’);
A Further Look At Processing
It disentangles applications as it completely incorporates the ideas of tables and streams, permitting joining tables that speak to the present condition of the world with streams that speak to occasions that are going on the present moment.
A point in Apache Kafka can be created as either a STREAM or a TABLE in KSQL, contingent upon the proposed semantics of the preparing on the theme. For example, in the event that you need to peruse the information in a point as a progression of free qualities, you would utilize CREATE STREAM.
A case of such a stream is a theme that catches site visit occasions where each site visit occasion is random and autonomous of another. On the off chance that, then again, you need to peruse the information in a subject as a developing accumulation of updatable qualities, you’d utilize CREATE TABLE. A case of a theme that ought to be perused as a TABLE in KSQL is one that catches client metadata where every occasion speaks to most recent metadata for a specific client id, be it client’s name, address or inclinations.
Taking A Deeper Look Inside KSQL
There is a server process which executes inquiries. An arrangement of forms keeps running like a bunch. You can progressively include all the more, preparing limit by beginning more examples of the server.
These occasions are error tolerant: on the off chance that one comes up short, the others will assume control over its work. Questions are propelled utilizing the intelligent KSQL order line customer who sends directions to the group over a REST API.
The order line enables you to investigate the accessible streams and tables, issue new questions, check the status of and end running inquiries. Inside, there is assembled utilizing Kafka’s Streams API; it acquires its flexible adaptability, propelled state administration, and adaptation to non-critical failure, and support for Kafka’s as of late presented precisely once preparing semantics.
The server installs this and includes top an appropriated SQL motor (counting some extravagant stuff like programmed byte code age for question execution) and a REST API for inquiries and control.
Of KSQL Tables And Logs
In a social database, the table is the center reflection, and the log is a usage detail. In an occasion driven world with the KSQL database is turned back to front, the center reflection isn’t the table; it is the log.
- The tables are simply gotten from the log and refreshed ceaselessly as new information touches base in the log. The focal idea is Kafka and KSQL is the tool that enables you to make the data appear and speak to people as consistently refreshed tables.
- You would then be able to run point-in-time questions (coming soon) against such spilling tables to get the most recent incentive for each key in the log, in a progressing style.
- Turning the database back to front with Kafka and KSQL greatly affects what is currently conceivable with every one of the information in an organisation that can normally be spoken to and prepared in a spilling design.
The Kafka log is the center stockpiling for distributing information, permitting same information that goes into your disconnected information stockrooms and is to now accessible for stream preparing.
Everything else is a gushing appeared to see over the log, be it different databases, seek lists, or other information serving frameworks in the organisation. All information advancement and ETL expected to make these determined perspectives should now be possible in a spilling style utilizing KSQL.
Checking, security, inconsistency and risk discovery, examination, and reaction to disappointments should be possible progressively versus when it is past the point of no return. This is accessible for pretty much anybody to use through a straightforward and recognizable SQL interface to all your Kafka information.
- Using KSQL For Working With Data
Some of the most common use cases for using real-time data streams include:-
- Putting schema to data.
- Filtering data.
- Changing dataframes.
- Changing the serialization format.
- Enriching data streams.
- Unifying multiple data streams.
A Step By Step Procedure to get started with KSQL
The information coming in is JSON—yet with no proclaimed construction in that capacity. As a structure, Kafka Connect can amazingly enroll a composition for inbound information that it serializes as Apache Avro, yet the REST connector here is fundamentally simply pulling string information from the REST endpoint, and that string information happens to be JSON.

- Along these lines, the principal thing to do is proclaiming a starting statement for the source information from every theme. Note that the construction changes marginally to consider the information from one of the stations that incorporate an exhibit.
- Utilise KSQL’s capacity to re-serialize and convert the crude JSON information into Avro.
- The favorable position here is that any application downstream—regardless of whether it’s another procedure, Kafka Connect or a Kafka customer—can work with the information straightforwardly from the point and get the diagram for it from the Confluent Schema Registry.
- To do this, utilize the CREATE STREAM… AS SELECT proclamation with the VALUE_FORMAT indicated as a major aspect of the WITH proviso:
- To do this, we can utilise KSQL’s INSERT INTO command. This streams the aftereffects of a SELECT proclamation into a current target STREAM.
- Make the underlying STREAM utilizing CREATE STREAM… AS SELECT.
- In light of the above information show, the special key for information is a composite of the station, perusing compose and timestamp.
- The message key is essential as it characterizes the segment on which messages are put away in Kafka and is utilized in any KSQL. Right now there’s no key set, so information for a similar station and perusing compose could be scattered crosswise over segments.
- For a couple of columns of information this may not make any difference, but rather as volumes increment it turns out to be more critical to consider. It’s likewise appropriate to the strict requesting ensure that Kafka gives, which just applies inside a parcel.
- Past separating, databases can be utilized to make inferences in view of the approaching information. How about we take the case of dates.
- And also the crude timestamp of each perusing that we get, it may be the case that for usability downstream we need to likewise include sections for the only year, month etc.
- The TIMESTAMPTOSTRING capacity and DateTime design strings enable you to achieve these assignments effectively.
Talking Commands
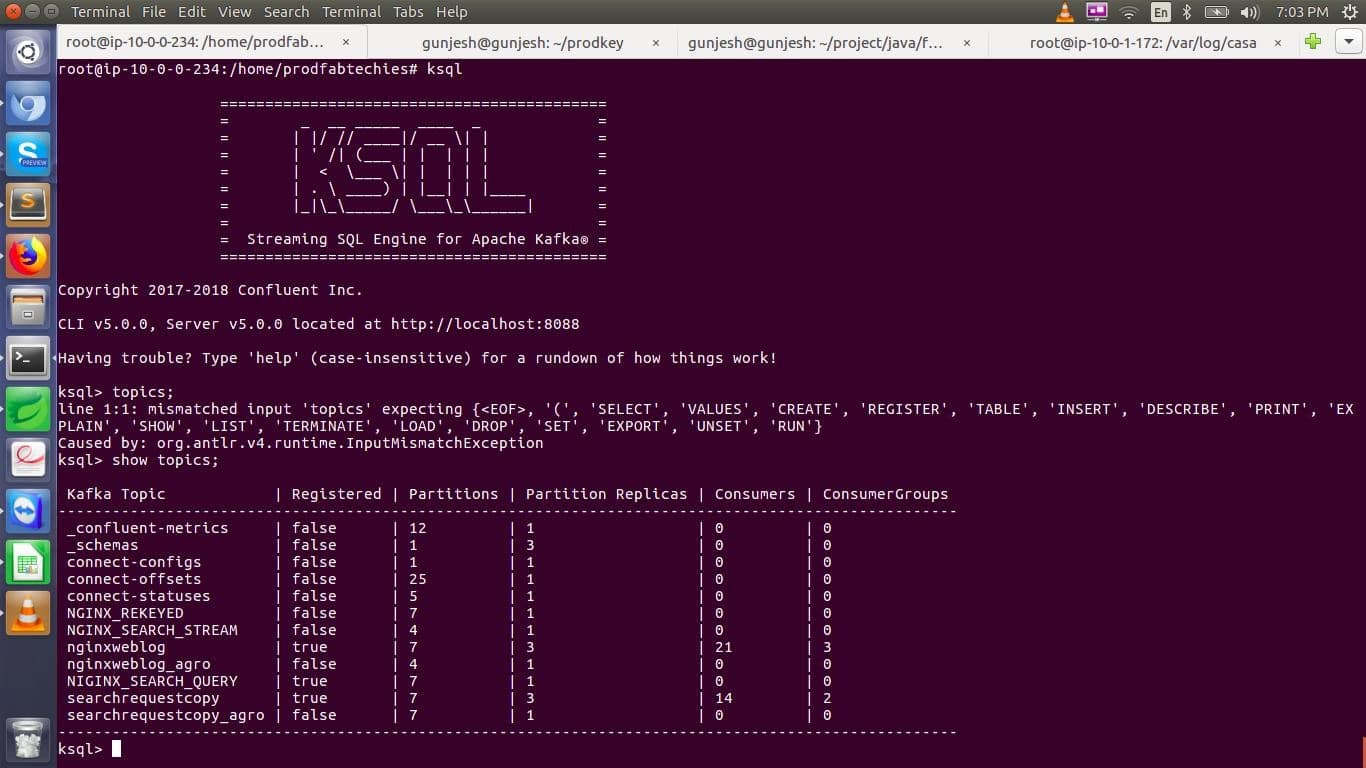
You can start the KSQL Server with the ksql-server-start command and applying the CREATE STREAM command.
After inserting the required command on the data set use the DESCRIBE command to see the schema of the new stream.
While you test out the codes on the platform, it’s useful to start building scripts with Gradle, Kotlin. The build.gradle file needs the Kotlin plugin by using the command:-
buildscript {
dependencies { classpath “org.jetbrains.kotlin:kotlin-gradle-plugin:1.2.51” }
}
apply plugin: “java”
apply plugin: “kotlin”
When the time comes to add dependencies, just type:-
compile “org.jetbrains.kotlin:kotlin-stdlib-jdk8:1.2.51”
compile “com.github.javafaker:javafaker:0.15”
It’s best suited to use Jackson for JSON (de-)serialization, but let’s not forget to add the Kotlin module to (de-)serialize Kotlin data classes:-
compile ‘com.fasterxml.jackson.core:jackson-databind:2.9.6’
compile ‘com.fasterxml.jackson.module:jackson-module-kotlin:2.9.6’
compile ‘org.apache.kafka:kafka-clients:2.0.0’
Now you’re finally set and can work on the project from the extension in IntelliJ and start coding.
Models And Messages
Create a Kafka Producer to send messages to Kafka:-
private fun createProducer(brokers: String): Producer<String, String> {
val props = Properties()
props[“bootstrap.servers”] = brokers
props[“key.serializer”] = StringSerializer::class.java.canonicalName
props[“value.serializer”] = StringSerializer::class.java.canonicalName
return KafkaProducer<String, String>(props)
}
Now create a mock model to hold the data:-
data class Type(
val Parameter: String,
val Parameter: String,
val Parameter: Date
)
Similar, like a POJO in Java other models, can be implemented.
To generate data, remember that Kotlin doesn’t force you to assign the fields by name, but this makes the code more readable.
Next create a JSON mapper using the command:-
val jsonMapper = ObjectMapper().apply {
registerKotlinModule()
disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS)
setDateFormat(StdDateFormat())
}
The mapper serves as a great way to serialize all objects. This can then be finally sent to Kafka KSQL as a JSON object.
val futureResult = producer.send(ProducerRecord(personsTopic, fakePersonJson))
futureResult.get()
An important thing to note is that the get() function was called to wait for the written acknowledgement without which messages can still be sent. However, they would be lost without users knowing about the failure.
Code Tests
Start the zookeeper extension and type
$ bin/zookeeper-server-start etc/kafka/zookeeper.properties
… [2018-08-01 09:57:11,823] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
This indicates that ZooKeeper is now running on port 2181. Time to start start Kafka:
$ bin/kafka-server-start etc/kafka/server.properties
…
[2018-08-01 09:57:32,511] INFO Kafka version : 2.0.0-cp1 (org.apache.kafka.common.utils.AppInfoParser)
Create a topic for the stream and start the application in the IDE and view all data imports.
$ kafka-topics –zookeeper localhost:2181 –create –topic persons –replication-factor 1 –partitions 4
$ kafka-console-consumer –bootstrap-server localhost:9092 –topic sample
{“Sample”:”Sample”,”Sample”:”Sample”,”Sample”:”Sample”}
Additional processing of the entered data can be done by adding and executing KSQL commands that share certain syntactic arrangements with SQL. More advanced processing would require other Kafka extensions.
Bringing It To An End
Users might feel foreshadowed by the software’s young entry into the data world but shouldn’t feel discouraged in using it. KSQL might be fairly new when compared to more analytics centered software but functions as a great addition and back-end to a variety of applications.
It majorly has been in use as a lightweight and compact relational database management tool with a greater emphasis on model building and interlinking large-scale databases with innumerable records. Combined with the prepackaged perks of the Kafka family library, it is a great way to step forth into data processing.